Contemporary large-scale visual language models
(VLMs) exhibit strong representation capacities, making
them ubiquitous for enhancing the image and text under-
standing tasks.
They are often trained in a contrastive
manner on a large and diverse corpus of images and cor-
responding text captions scraped from the internet. De-
spite this, VLMs often struggle with compositional reason-
ing tasks which require a fine-grained understanding of the
complex interactions of objects and their attributes.
This failure can be attributed to two main factors: 1) Contrastive
approaches have traditionally focused on mining negative
examples from existing datasets. However, the mined nega-
tive examples might not be difficult for the model to discrim-
inate from the positive. An alternative to mining would be
negative sample generation 2) But existing generative ap-
proaches primarily focus on generating hard negative texts
associated with a given image. Mining in the other di-
rection, i.e., generating negative image samples associated
with a given text has been ignored.
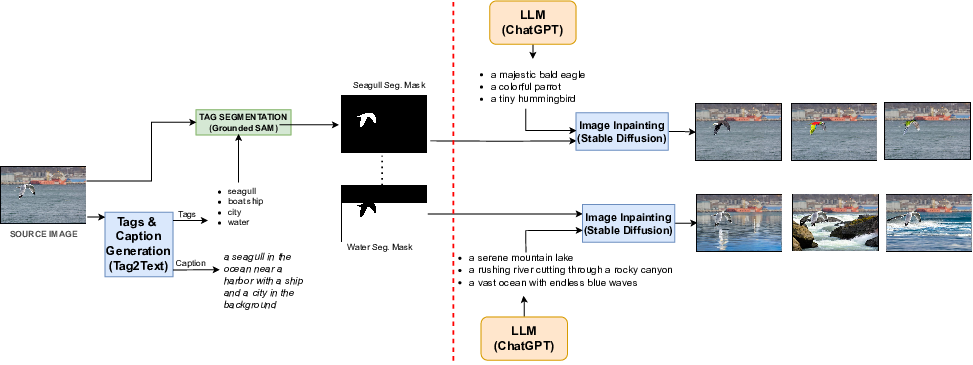
To overcome both these limitations, we propose a framework that not only mines
in both directions but also generates challenging negative
samples in both modalities, i.e., images and texts. Leverag-
ing these generative hard negative samples, we significantly
enhance VLMs’ performance in tasks involving multimodal
compositional reasoning.